Spark Tutorial Part 3: Apache Spark Architecture
by Ayush Vatsyayan
In the previous post we have installed Spark development environment up and running. Now I’ll explain the Apache Spark basic concepts. These concepts will provide insight into how Spark works.
Spark Architecture
Spark application consist of a driver process and a set of executor processes. Driver program is the one that contains the user’s main() method and executes various parallel operations on a cluster.
The executors are responsible for actually carrying out the work that the driver assigns.
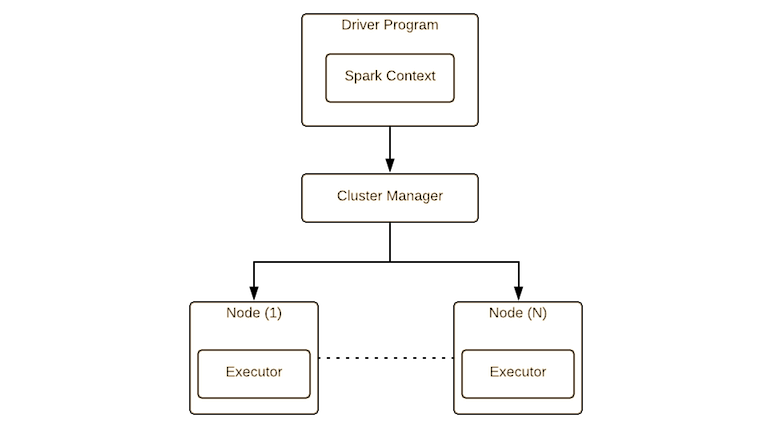
Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in the main program i.e. driver program. To run on a cluster, the SparkContext will connect to the cluster manager (such as Apache Yarn or Mesos). Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for the application. Next, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks to the executors to run.
Resilient Distributed Datasets (RDDs)
What is RDD?
Resilient distributed dataset (RDD) is a fault-tolerant, read-only, partitioned collections of records that can be operated on in parallel. There are two ways to create RDDs: parallelising an existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, etc. Spark makes use of the concept of RDD to achieve faster and efficient MapReduce operations.
Why RDD?
In general, there are two options to make a distributed dataset fault-tolerant: checkpointing the data or logging the updates made to it. Checkpointing the data is expensive, as it would require replicating big datasets across machines over the data- center network. Same is with logging updates if there are many of them. Whereas RDD only remember the series of transformations used to build an RDD (i.e., its lineage) and use it to recover lost partitions.
RDD in Spark Programming
Spark provides the RDD abstraction through a different language-integrated API such as Scala, Python, R, and Java. To use Spark, we have to write a driver program that connects to a cluster to run workers (called as executors). The workers are long-lived processes that can cache RDD partitions in RAM.
The arguments to RDD operations, like map, are provided by passing closures (function literals). These these objects are represented as Java objects that can be serialized and loaded on another node to pass the closure across the network.
Applications Not Suitable for RDDs
RDDs are best suited for applications that perform bulk transformations that apply the same operation to all the elements of a dataset. RDDs would be less suitable for applications that make asynchronous fine-grained updates to shared state, such as a storage system for a web application or an incremental web crawler and indexer. For these applications, it is more efficient to use systems that perform traditional update logging and data checkpointing.
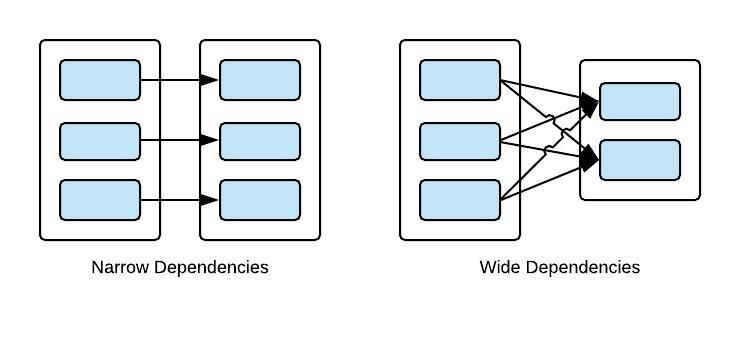
Narrow and Wide Dependencies in RDD
Narrow dependencies: where each partition of the child RDD depends on a constant number of partitions of the parent for e.g. map.
Wide dependencies: where each partition of the child can depend on data from all partitions of the parent for e.g. groupByKey.
DAG (Direct Acyclic Graph) Scheduler
DAG scheduler is responsible for examining the the target RDD to build a DAG of stages to execute. The scheduler places tasks based on data locality to minimize communication. If a task needs to process a cached partition, it send it to a node that has that partition
Summary
I have presented the fundamental concept of Spark i.e. RDD. We now have clear understanding of how Spark works internally. In the next article we will start executing the hands-on example as we proceed.
Subscribe via RSS