Spark Tutorial Part 4: Getting Started with DataFrames
by Ayush Vatsyayan
This article in our Spark Tutorial series demonstrates the reading of data into Spark DataFrame and applying different transformations on it.
Prerequisites: Set up Spark development environment and review the Spark Fundamentals.
Objective: To understand Spark DataFrames and load data into Apache Spark.
Overview
It’s much easier to program in Spark due to its rich APIs in Python, Java, Scala, and R.
This richness is gained from Apache Spark’s SQL module that integrates the relational processing (e.g. declarative queries and optimized storage) with Spark’s functional programming API.
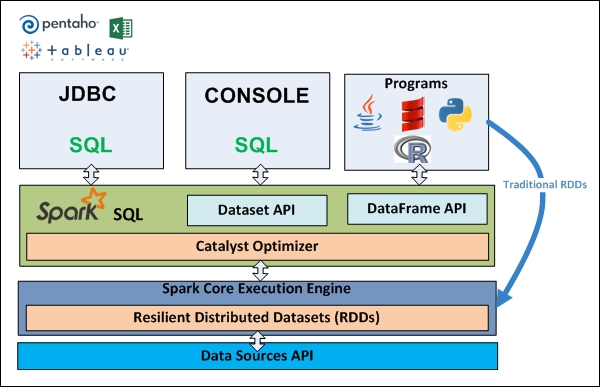
Compared to RDD, Spark SQL makes two main additions:
- Offers much tighter integration between relational and procedural processing, through a declarative DataFrame API that integrates with procedural Spark code.
- Includes a highly extensible optimizer, Catalyst, built using features of the Scala programming language, that makes it easy to add composable rules, control code generation, and define extension points.
In summary Spark SQL is an evolution of both SQL-on-Spark and of Spark itself, offering richer APIs and optimizations while keeping the benefits of the Spark programming model.
Datasets and DataFrames
A DataFrame is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations. It is a distributed collection of data, like RDD, but organized into named columns (i.e., a collection of structured records).
DataFrame provides Spark with more information about the structure of both the data and the computation. This information can be used for extra optimizations.
Unlike the RDD API, which is general and has no information about the data structure, the DataFrame API can:
- Perform relational operations on RDDs and external data sources
- Enable rich relational/ functional integration within Spark applications.
DataFrames are now the main data representation in Spark’s ML Pipelines API.
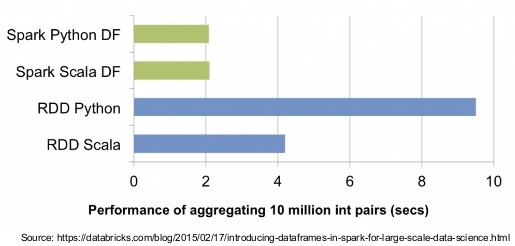
Another improvement is the Dataset API which was added in Spark 1.6 that provides the benefits of RDDs (strong typing, ability to use powerful lambda functions) with the benefits of Spark SQL’s optimized execution engine.
The Dataset API is available in Scala and Java. Python and R does not have the support for the Dataset API, but due to their dynamic nature, many of the benefits of the Dataset API are already available.
Example: Amazon product review data
The dataset for Musical Instruments can be downloaded from Stanford Network Analysis Project.
This dataset contains product reviews for Musical Instruments from Amazon. Once downloaded, we will put the downloaded csv files into HDFS.
Column Definitions
- reviewerID - ID of the reviewer, e.g. A2SUAM1J3GNN3B
- asin - ID of the product, e.g. 0000013714
- reviewerName - name of the reviewer
- helpful - helpfulness rating of the review, e.g. 2/3
- reviewText - text of the review
- overall - rating of the product
- summary - summary of the review
- unixReviewTime - time of the review (unix time)
- reviewTime - time of the review (raw)
Load data into HDFS
Once the data is downloaded, put the data into HDFS by following below steps:
- Create directory:
hdfs dfs -mkdir examples - Put downloaded json file into example directory in HDFS:
hdfs dfs -put Musical_Instruments_5.json examples - Print top 4 rows from file in HDFS:
hdfs dfs -cat examples/Mu*.json | head -n 4
Read data into Spark from HDFS
For loading data into spark we need to initialize the SparkSession object, which is the entry point to programming Spark with the Dataset and DataFrame API.
In case we are using the spark-shell, the SparkSession object will be created automatically. Otherwise we can create is using below command:
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark example")
.getOrCreate()
Once SparkSession is initialized, we can read the csv file into spark:
val df = spark.read.json("examples/Musical_Instruments_5.json")
Explore and Transform Data
- Extract month and year: For this we have used from_unixtime function, which converts the number of seconds from unix epoch (1970-01-01 00:00:00 UTC) to a string.
import org.apache.spark.sql.functions._ val df1 = df.withColumn("date",from_unixtime($"unixReviewTime")).withColumn("year",year($"date")).withColumn("month", month($"date")) - Count of Review by year and month
df1.groupBy("year", "month").count().sort(desc("count")).show() - Average reviews per user
df1.count()/df1.select("reviewerID").distinct().count() - Average count of reviews per product
df1.groupBy("asin").agg(avg("overall"),count("overall")).sort(desc("count(overall)")).show() - Top 10 rated product
df1.groupBy("asin").agg(avg("overall"),count("overall")).sort(("avg(overall)")).show()
Summary
I have explained the concept of DataFrames along with reading a json dataset into the Spark. We have also looked at creating new columns and performing different summarization as well.
In the next article we will carry forward this example and will try to perform some text analytics on the review summary.
Subscribe via RSS